
Subversion (SVN) and Git: comparative analogues
What is this document?
The purpose of this document is to detail how Subversion handles branching, tagging, merging and change tracking under the covers in order to address some common misunderstandings when dealing with migrations. The overall course of this document will show that branches and tags are significant because teams treat them as such, and not because subversion tracks them as such. We will also discuss snapshots and diff, as well as the merging process. Subversion is fundamentally different from how Git works, which creates Refspecs for tags and branches, signifying that they are tracked differently than normal files in the existing folder. Git is always working on a branch, even if that branch is master, so your changes are always tracked in relation to a branch.
Subversion: a technical deep-dive
While it is true that you can track branches programmatically while developing with subversion, this is something that needs to be done externally to subversion, either manually by teams or by using a platform, such as FishEye or TeamForge.
Since tags and branches are implemented via directory copies in Subversion, they are not really first-class concepts. This means that FishEye has to determine branch and tag information by examining the paths involved in Subversion operations and matching these against branch and tag conventions used in the repository. Since these conventions are not fixed, you may need to tell FishEye what conventions you use in your repository. By default FishEye has some inbuilt rules which handle the most common conventions typically used in most Subversion sites. If, however, you've decided to use a custom convention, you can define custom rules to describe what your tag/branch structure looks like. These settings can be edited on the 'Add Repository' or 'Edit Repository' pages in the FishEye Administration pages.
What about Merge Tracking?
Subversion certainly must track the changes somewhere if there's going to be any rolling back. This is where the svn:mergeinfo property comes in. As of Subversion 1.5, merge tracking is a useful feature for tracking the merge history. During each merge operation, the svn:mergeinfo property is changed to record the merge. The svn:mergeinfo property will live on the target in this case. Unfortunately, subversion only records where changes are merged from, not where they are merged to. This presents a challenge when attempting to analyze a repository without having a defined convention.
Another challenge regarding merge tracking is the fact that it only updates the property after you merge. This means that we may have countless branches that are never merged, and therefore would never be recorded as having been so.
With the flexibility of having trunk or not, or making some other folder serve as the trunk with a different name, having branches that aren't called "branches", or tags that aren't called "tags", branches that are never merged, and so forth, limitless possibilities exist wherein the developers using the system must track it themselves, or else an external system.
Branching: the logical flow
The user checks out a repository
The user creates a remote branch using
svn copy <source> <target>This copies the files with their history
This creates a new revision
There are no references to the original files or folders, but only log entries tracking the creation of the new file and marks the change as
Ain the history to denote added files
The may also switch to an existing branch (
svn switch https://www.example.com/svn/branches/v1p2p3)This triggers a series of cheap copies to be created. A cheap copy is essentially a link to the original file, and it updates the
symlink_targetfield in the localwc.dbThis action affects only the local working copy, and targets a remote directory for committing the changes to. No remote references are created at this point
The local
wc.db, or working copy database is updated with entries to be tracked, but they are tracked as normal files and folders
The user makes changes
This causes the changed files to be saved as new files, and no longer cheap copies
The user checks in the changes
This causes the files to be pushed to the targeted remote directory, as normal files and folders, with the checked-out revision number
There are no references to the branch itself, outside of the local working copy
The user merges the
branchto thetrunk(this can also happen in the working copy)This triggers merge tracking on the target to update the
svn:mergeinfoproperty for that revision
This flow seems logical enough, but it makes a few assumptions.
Assumptions:
We're merging to
trunk(this may not be true, and may be branch to branch)We're merging from a
branch(this can be from any directory)We're keeping our branches in the same parent folder (this may not be the case)
We're merging a folder and not individual files (we'll discuss this further down)
Consider the following layout:
In this example, we may have mergeinfo for each of the branches, but there is no way to map branches in our migration. This is because git-svn can look at a single directory per repository for branches. Is branch3 a branch of subfolder3, or is it a branch of some other directory? svn copy doesn't leave a trail of where it was copied from, only that it was newly added to the repository. If we treat each of these as branch folders then we need 3 separate repositories, as git-svn cannot multi-map.
Another point to note is that svn copy does not have to be used for branching and tagging. It can be used for other purposes, and very often is used for such.
Finally, the svn:mergeinfo property is only available if there is a merge. If you do not merge, there is no merge tracking.
What about the SQLite database?
SQLite database?Merge history is not stored in the SQLite database. This is documented in Apache's documentation
The SVN Database: wc.db layout
wc.db layoutName
Data type
Primary Key
Foreign Key
Unique
Check
Not NULL
Collate
Default Value
wc_id
INTEGER
:key:
:link:
:white_check_mark:
NULL
local_relpath
TEXT
:key:
:white_check_mark:
NULL
op_depth
INTEGER
:key:
:white_check_mark:
NULL
parent_relpath
TEXT
NULL
repos_id
INTEGER
:link:
NULL
repos_path
TEXT
NULL
revision
INTEGER
NULL
presence
TEXT
:white_check_mark:
NULL
moved_here
INTEGER
NULL
moved_to
TEXT
NULL
kind
TEXT
:white_check_mark:
NULL
properties
BLOB
NULL
depth
TEXT
NULL
checksum
TEXT
:link:
NULL
symlink_target
TEXT
NULL
changed_revision
INTEGER
NULL
changed_date
INTEGER
NULL
changed_author
TEXT
NULL
translated_size
INTEGER
NULL
last_mod_time
INTEGER
NULL
dev_cache
BLOB
NULL
file_external
INTEGER
NULL
inherited_props
BLOB
NULL
Sample wc.db entry
wc.db entryOur initial thought here is to use either the symlink_target field, or the properties field to determine what this branch points to. Unfortunately, as we can see from the database info above, there are no references to this being a branch, other than the folder name itself. The symlink_target field is updated in the working copy when you use svn switch. This triggers a cheap copy to be created, but this means that files are created upon the commit. When they are created they are no longer symlinks, and are not tracked as such. This leaves us unable to find the target outside of our local working copy.
Dealing with nested repositories
It is fairly common to have repositories with multiple projects in them. The normal structure for this sort of project layout is as follows:
If all projects in Subversion were managed with this structure then migrating them to Git would be a pretty straight-forward process. The reality is, however, there are many projects where branches, tags and trunk are not consistently structured. Consider the following layout:
In this example we have files in the root of the directory, and a separate trunk folder. The migration of this repository to git requires that either the repository root or trunk be mapped to a git master. They cannot both map. If we map trunk to master then we will be ignoring the files and folders at the root level. This is usually not the desired effect. A solution would be to move the files in the root of the repository into the trunk folder prior to migrating, or else treat the root of the repo as trunk.
Another challenge with this structure is the fact that we have branches, tags and trunk in nested folders, but not following any particular convention. As discussed in the svn:mergeinfo section, these folders will track where they were merged from. If we have repository/folder2/subfolder2/branches/branch1/, we cannot tell where it was merged to without analyzing each file in the repository at each revision. This seems logical enough, but if we have this branch merged into multiple places then we lose the ability to determine the target. Consider the following as an example:
In the example above we have multiple target directories, which would lead us to determine that folder2/subfolder2/branches/branch1/ is a branch, but does not tell us what it is a branch of. Is it a branch of trunk? Is it a branch of folder2/subfolder2/trunk/?
We could then take a look at the svn log to see where svn copy originally created the branch. This, again, seems like the logical next step. The challenge with this, however, also lies in consistency. Subversion allows for any folder to be merged into any folder, which means that you do not have to create a branch using svn copy, and this often proves to be the practice. Additionally, since there is no difference between how subversion treats tags and branches, there would be no way to programmatically discover a repository layout without the administrator providing parameters by which their teams abide.
What about svn:externals?
svn:externals?Subversion provides the ability to set svn:externals when working with multiple revisions or repositories at once. This really seems like a perfect mapping to git submodules, but they differ in many respects. The challenge with using svn:externals is the same challenge we face with other potentials: namely, inconsistent use and formatting. It is somewhat uncommon for teams using nested projects to treat them as externals, so relying on this property would leave us with no information in most cases. Another challenge is that the property for svn:externals is applied to a particular revision, and not maintained across revisions. This means we can have a different set of externals applied to a folder for each revision, and it cannot provide a definitive list of URL's to use as git submodules.
SVN and Git: comparative analogues
When considering a migration from subversion to git, there are a few technical and idealogical differences that are generally misunderstood. This usually leads to a significant expenditure of resources trying to accomplish what can't reasonably be expected to succeed.
Snapshots vs Diffs
Many teams will ask about their binaries when migrating, and argue that subversion has no issue tracking changes in binaries. What is generally misunderstood here is that subversion maintains snapshots, whereas git tracks diffs. There is a fundamental difference between the two which should be properly understood when comparing the two systems.
Snapshots
A snapshot is a point in time reference to block-level data. When there is a change made, a delta, or incremental difference is recorded of the block-level state, and nothing is or can be recorded about the data itself, just the block changes. If we revert to an older state then the blocks are changed back. The consequence is that our data (or contents) will match the old data, but the subversion server is not aware of the contents, only the block changes in the successive versions of files.
Subversion does have a command to view the diffs (svn diff), but this is fundamentally different than that of git. In the case of subversion, it will read the block data from the old revision, then read the block data from the new revision and output the difference. This difference is read in realtime and not stored as a difference in contents.
A challenge commonly faced with the snapshot approach is that you cannot have two people working on the same file at once. This often causes merge conflicts because the changes are tracked at the block-level and not tracked in the contents.
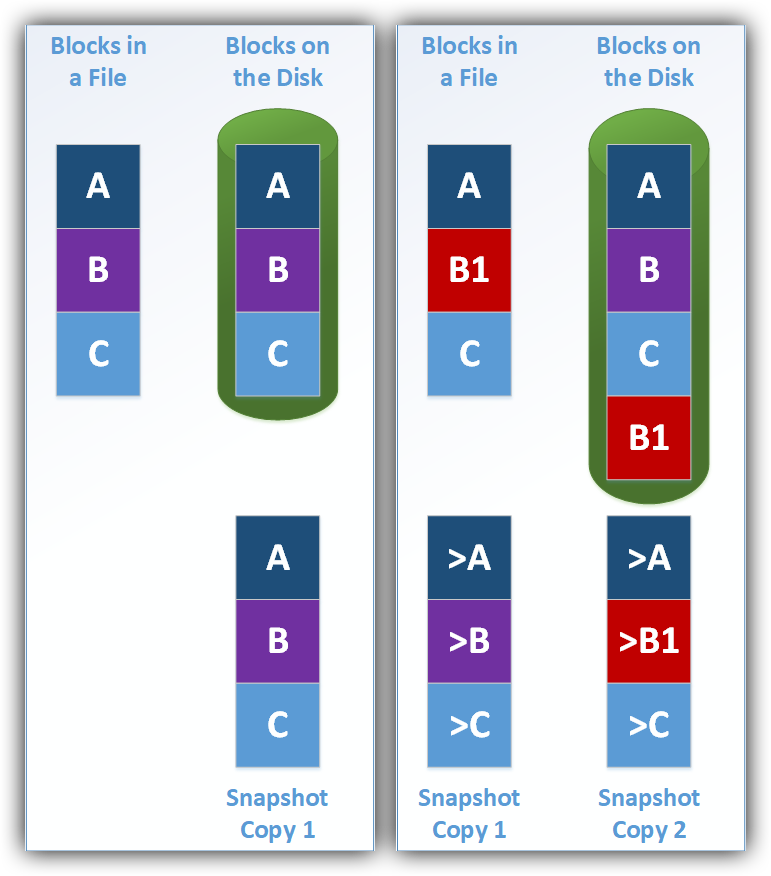
Snapshots record only the block-level changes since the last snapshot.
Diffs
A diff is comparison of changes in the contents between two files. For text files, this means that it will look at deleted lines, added lines and changed lines, and store a record of the differences. For binary files, this means that it cannot view them, and stores the entire file as a new copy. When using diff, there is no attempt to view the block-level differences. The resulting outcome is that you will end up with multiple full copies of the binary file in your repository and history.
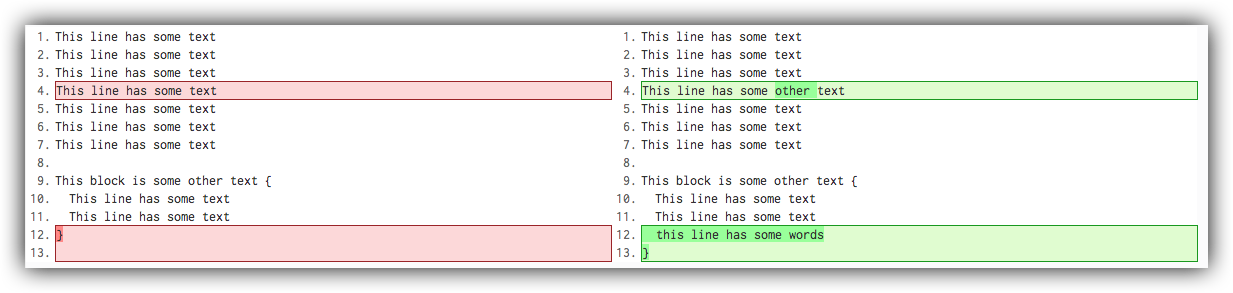
Diff does not track the block-level differences, only contents.
Merge operations
Subversion allows for very flexible merging, and accommodates several scenarios that Git does not. One such scenario is the ability to merge individual files between branches or folders. In git we can merge branches to branches, but not individual files, and it must be a merge between branches. With subversion, however, you can merge individual files between any folder, which allows a user to be very granular in their merge operations.
On the surface this seems like an oversight in git, or a significant shortcoming. In practice, however, having the flexibility to merge like this has historically prevented teams for having a unified workflow, and hampers collaboration. Teams and individuals have limitless flexibility to practice bad habits and you lose definitive controls around workflow. This also presents a problem when attempting to dynamically discover a repository layout based on the repository history.
Migrating history: revision vs commit
In subversion, revisions and commits are inseparable in practice, but in git they are distinctly differentiated in theory and in practice.
Commits
A commit, in its simplest form, is a record of the changes made, along with data around the changes. In subversion, this commit will include an optional comment, the timestamp and the author's username. In git, this commit will include the author's name, email, SHA1 hash, optional comment, and timestamp. When working with subversion, committing to a repo checks in the files to the remote repository. In git, a commit happens locally, and changes aren't pushed to the remote until the git push command is issued. There is a bit more context around this in the section on revisions.
Revisions
A revision, or version, is any change in form. In SVN, a revision is the state at a point in time of the entire tree in the repository.
Quote from Subversion in Action:
Unlike those of many other version control systems, Subversion's revision numbers apply to entire trees, not individual files. Each revision number selects an entire tree, a particular state of the repository after some committed change. Another way to think about it is that revision N represents the state of the repository filesystem after the Nth commit. When Subversion users talk about “revision 5 of foo.c”, they really mean “foo.c as it appears in revision 5.” Notice that in general, revisions N and M of a file do not necessarily differ!
In effect, this means that a commit and revision within subversion are handled the same. Since the commits can only happen when changes are pushed to the subversion server, the revision is updated when the commit is created. Creating a new commit will create a new revision. Subversion's central focus is revisions.
In git, commits update the commit objects, but revisions are changed and tracked for each file, not for the entire tree. This provides flexibility with undoing changes at a granular level, and helps to avoid merge conflicts.
History
The consequence of these differences becomes more apparent when we're mapping subversion history to git. The level of data tracked by subversion in the commits does not map directly to git, and requires significant modification to retain and map. The lack of a one-to-one means that the migrated history becomes more of a "best effort storytelling" than actual history. It may be mostly accurate, but it won't paint the picture we'd want.
Subversion:
Git:
Given the data above we can see that subversion logs significantly less data in each revision than what we see in our git commits. Mapping this info means adding data that was never there, and this inherently disqualifies any history from being usable in an audit. We will also note that a revision in subversion applies to all files in the tree, whereas in git we will have a revision for each file.
Conclusion
Subversion is fundamentally different in how it operates from Git. Much of the inherent functionality in Git is assumed to be present in subversion, and vice-versa, but instead subversion relies heavily on human behavior and has some flexibility that was intentionally avoided in git. Branches in subversion are branches because they are treated like branches. Tags in subversion are tags because they're treated like tags. Nested repositories are nested repositories because they're treated like nested repositories. Subversion can merge any file to any other file, and any directory to any directory. Subversion tracks changes, but not with the granular metadata that we often want. Third-party platforms, such as FishEye, TeamForge and GitHub provide some this metadata through the use of their own database and cataloging, but there is still a need for teams to define their own behaviors for these platforms.
References
Last updated